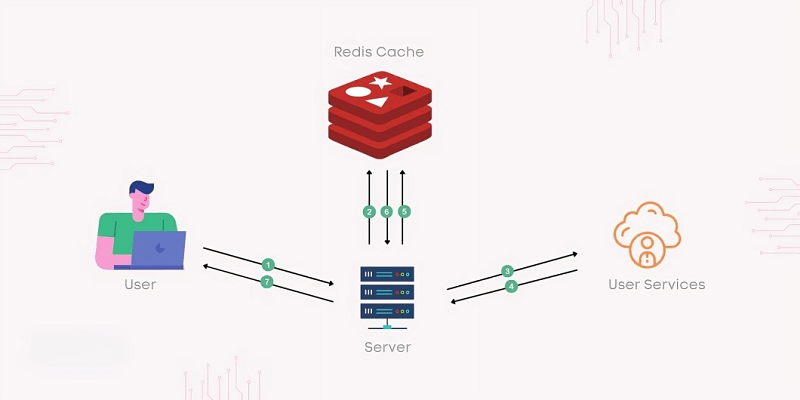
Redis (Remote Dictionary Server) is a database that does not adhere to conventional databases but functions as a memory storage system with its own approach to managing data through speed and scaling. While Redis operates as a cache and a database, it stores data in RAM memory, making it possible to achieve both high-speed reading and writing.
It excels at real-time applications, caching sessions, queuing processes, and providing quick data access. Redis's built-in replication, persistence choices, and clustering capabilities assure data stability, scalability, and availability.
-
- History And Evolution of Redis
- Redis Configuration File and Setup
- A Look Into Redis Database
- Client and Server roles in the Redis Cluster Nodes
- Ports and port ranges used by Redis Enterprise Software
- Ubuntu conflicts with port 53
- Redis client libraries
- Pros and Cons of Redis
- Redis vs. Memcached
- Redis And VPSServer
Explore the world of Redis with this in-depth guide, where we uncover its powerful capabilities, features, and top practices for maximizing data performance. From the basics to advanced strategies, discover how Redis transforms data management, enhances application speed, and guarantees reliability in challenging settings.
History And Evolution of Redis
Salvatore Sanfilippo built Redis, an open-source in-memory data-structure store, in 2009, fueling its widespread popularity, utility across varied scenarios, and versatility with multiple datatypes.
Redis has significantly changed over time with new features and improvements. Adding persistence alternatives such as RDB and AOF improved data durability, while replication and clustering features increased fault tolerance and scalability.
Redis now supports real-time analytics, messaging, job queues, geospatial indexing, and more use cases in addition to caching. Its support for numerous programming languages and substantial community contributions helped solidify its place as a major NoSQL database.
Today, Redis is still innovating, with continuing projects focusing on performance improvements, security advancements, and advanced data manipulation features.

Redis Configuration File and Setup
The Redis configuration file is essential for configuring and modifying Redis instances to meet specific requirements. It enables administrators to adjust a variety of parameters, including network settings, memory management, persistence choices, security setups, and more.
By modifying the Redis configuration file, users can improve performance, maintain data durability through appropriate persistence techniques, establish access control and authentication settings to improve security and fine-tune Redis behavior based on workload and environment.
Setting up Redis' configuration file allows you to alter numerous aspects of its behavior. Here is a quick rundown of the Redis configuration:
-
The default configuration file for Redis is in the installation directory and is called "redis.conf.".
-
The settings of port number, data persistence options, and security setups can be put in place through the Redis configuration file.
-
Configure the Redis port to set the port where Redis will listen for client connections.
-
To ensure data durability, configure data persistence using options such as snapshots, append-only files, or a combination of the two.
-
Enable security options like authentication to limit access to the Redis server.
-
Set up memory-related settings—like maximum memory limits and rules for eviction—according to the needs of the system and the availability of resources.
In this manner, by simply changing those options in the Redis configuration file, we may tune Redis precisely as requested by the application, achieving better performance.
A Look Into Redis Database
Redis in its database and primary features are given below.
-
Strings are simple data types that can represent text or binary data.
-
Lists are ordered collections of strings, with operations made standard to include push and pop and to query elements between a range.
-
A set is an unordered collection of unique strings representing basic set operations.
-
Sorted Sets are similar to sets but have an associated score, allowing for sorted retrieval by score.
-
Hashes help represent objects or structured data by mapping string fields to string values.
-
Bitmaps are data structures that, very compactly, provide a way to carry out bit operations of setting, clearing, or counting bits in a very space-efficient manner.
-
HyperLogLogs are approximate data structures used to estimate the cardinality of distinct elements in a set.
Redis's in-memory design allows swift operations, making it ideal for use cases needing quick data access. It provides database persistence using a variety of mechanisms, including snapshots and append-only files (AOF), ensuring data durability and recovery in the event of a failure.
Additionally, Redis includes functionality such as transactions, publication/subscription messaging, and automatic failover for high availability configurations. Its client-server design enables clients to communicate with the Redis server via a network, using Redis commands to conduct data operations and manipulations.
Client and Server roles in the Redis Cluster Nodes
The Redis cluster protocols assign various roles to clients and servers as they collaborate to manage and distribute data across the cluster. Here is a summary of these roles:
Client Role
The client can either be an application or a service that is talking to the Redis cluster for both reading and writing into the data. The clients can connect to the cluster with either the Redis client library or the command line interface (CLI).
A command can be submitted to any nodes (servers) that form the Redis cluster. The client library, or CLI, routes commands to the proper node based on the cluster's topology and critical hashing.
Server Roles
Master Nodes:
In a Redis cluster, master nodes handle write operations from clients (SET, DEL, etc.). Each master node is the primary owner of a subset of the cluster's data (known as hash slots).
Master nodes replicate data to their slave nodes to ensure fault tolerance and high availability. Clients can connect to master nodes to perform read and write activities.
Slave Nodes:
Slave nodes replicate data from the master node and serve as backups. They handle read operations (GET, EXISTS, etc.) from clients but do not take write commands directly. If a master node doesn't work, one of its slave nodes can be upgraded to a master, ensuring service continuity.
Sentinel Nodes:
Sentinel nodes monitor the health and status of the cluster's master and slave nodes. If the current master becomes unavailable, they can execute automatic failover by promoting a slave to master status. Sentinel nodes help ensure the Redis cluster remains highly available and can recover from node failures automatically.
Ports and port ranges used by Redis Enterprise Software
Redis Enterprise Software uses specific ports and port ranges for its many features, which are divided into three categories: internal, external, and active-active. Let's look at each category to understand the ports and their purposes better.
Internal Ports
Internal ports facilitate communication between or within-cluster nodes, enabling internal cluster activities, coordination, and data exchange.
6379 - Redis Default Port: This port is used to communicate between clients and servers in a Redis Enterprise cluster. Clients use this port to communicate with Redis nodes and execute data storage and retrieval actions.
6380 - Redis SSL Port: When SSL/TLS encryption is set for safe connection, clients connect to Redis nodes using this port. It maintains data security and integrity during transmission.
10000-15000—Intra-Cluster Communication: Redis Enterprise uses various ports within this range for internal communication between cluster nodes. These ports make it easier to manage clusters, synchronize data, and coordinate different Redis Enterprise components.
External Ports
External ports are accessible via external networks and are used to communicate with client applications, external monitoring resources, or other external organizations.
12000-13000 - Client Proxy Port: Redis Enterprise uses a variety of ports in this segment for client proxy services. These ports are open to clients and handle incoming requests, distributed across the Redis cluster for load balancing.
16379 - Redis Sentinel Port: Redis Sentinel interacts through this port for high availability and failover management. Sentinel nodes monitor Redis instances and coordinate failover procedures when primary nodes fail.
18000-18999 - REST API Ports: Redis Enterprise offers a REST API for cluster management, monitoring, and setup. Ports in this range are used for external API access, which enables administrators and developers to communicate with the Redis Enterprise cluster programmatically.
Active-Active Ports
Active-active ports are particular ports used in clusters that house Active-Active databases. These configurations use multiple active databases to conduct read and write operations simultaneously.
7000-7999 - Active-Active Communication: In an active-active Redis Enterprise configuration, where data is duplicated across multiple active-active regions to ensure high availability and disaster recovery, ports within this range are used for inter-region communication. These ports allow for data synchronization and coordination between active-active clusters, which ensures data consistency and robustness.
16380 - CRDT Replica Ports: When employing CRDT (Conflict-Free Replicated Data Types) for distributed data structures spanning active-active regions, Redis Enterprise communicates with CRDT replicas across this port range. This enables real-time conflict resolution and replica synchronization across regions.
18888 - Active-Active Global Service Port: This port is used for worldwide services in an active-active Redis Enterprise configuration. The port offers cross-region functionality, allowing communication between active-active clusters and coordinating global processes. Examples include global caching, distributed locking, and global indexes.
Overall, Redis Enterprise Software uses various ports for internal communication, external access, and active/active configurations. These ports provide safe, efficient, and scalable operations within Redis Enterprise clusters, catering to various use cases and deployment options.
Ubuntu conflicts with port 53
Ubuntu may encounter issues with Redis port 53 due to its typical use by the Domain Name System (DNS). This conflict frequently occurs when many services or applications seek to use port 53 at the same time, resulting in disruptions to DNS operation and network connectivity.
One prominent source of contention is the system-resolved service, which performs DNS resolution on Ubuntu computers. This service may bind to port 53 and serve DNS requests locally. However, if other services or apps demand access to port 53, conflicts may arise, resulting in DNS resolution troubles and service outages.
Firewall settings can worsen these issues. Ubuntu firewall settings, which are handled via tools such as UFW or iptables, may include rules for port 53. Incorrectly set firewall rules in Ubuntu can block or allow traffic on port 53 in ways that interfere with DNS services, resulting in connection issues and security hazards.
Additionally, in complex network configurations or settings with bespoke DNS configurations, conflicts over port 53 might occur when various DNS-related services or forwarding mechanisms are operating. This can cause unpredictable behavior, such as sporadic DNS problems and service disruptions.
To resolve port problems with port 53 on Ubuntu, follow the procedures below:
1. Identify Conflicting Services
Use tools like netstat or lsof to see which services or processes in Ubuntu use port 53. This will help you determine the cause of the conflict.
2. Adjust Firewall Rules
Review and modify firewall rules to ensure that port 53 is correctly set for DNS services while preventing unwanted access or conflicts with other apps.
3. Service Configuration
Configure DNS services, such as system-resolved or BIND, to use different ports as needed. This helps resolve conflicts and ensure that DNS-related services run smoothly.
4. Network Analysis
Conduct a thorough network investigation to discover any misconfigurations or overlapping services causing port 53 conflicts. Adjustments to network settings may be required for resolution.
Redis client libraries
Redis client libraries are useful for establishing and maintaining strong connections between applications and Redis servers. These libraries serve as vital interfaces, allowing for easy communication and data transmission across connection channels.
They are critical for optimizing connection performance, ensuring reliability, and increasing overall efficiency in Redis-based applications.
One of the key functions of Redis client libraries is to effectively manage connection pools. By managing a pool of connections, these libraries make it easier to establish and reuse connections, reducing overhead and latency in data transmission.
This connection pooling approach greatly improves the scalability and responsiveness of Redis-powered applications, particularly in cases involving high concurrency and frequent data exchanges.
Additionally, Redis client libraries include extensive connection management features, including timeouts, retries, and failover mechanisms. These capabilities improve application resilience by automatically addressing connection difficulties, allowing for ongoing operation even in demanding network conditions or server failures.
Furthermore, these libraries offer various configuration options for modifying connection settings, such as connection limits, timeouts, and buffer sizes, allowing for tailored performance based on unique application requirements.
In conclusion, Redis client libraries are essential tools for establishing and maintaining reliable connections between applications and Redis servers. Their wide capabilities in connection pooling, protocol support, and configuration flexibility make them critical components for creating high-performance and dependable Redis-based applications.
Pros and Cons of Redis
Benefits of Using Redis
High Performance:
Redis is said to be performing well due to its in-memory data storage. An in-memory database, Redis, runs directly from the RAM and serves data very fast compared to disk-based databases. It's convenient in applications requiring real-time data processing, cache, and low-latency operations.
Versatile Data Structures:
Redis supports several data structures within strings, hashes, lists, sets, sorted sets, bitmaps, hyperloglogs, and geospatial indexes, allowing developers to again choose the adequate data structure according to the matter in question, thus making a save and retrieval of data with much-optimized procedures.
For example, Redis' ability for sorted sets makes leaderboard implementations easier, while its geographic features enable location-based applications.
Cache Capabilities:
Redis is primarily used as a caching layer, and caching data is accessed very frequently. Hence, it has a deficient demand for hosting databases, improving overall application performance. In Redis, data is cached in such a way that response times are improved, latencies are reduced, and there is a better user experience. Hence, it is guaranteed that applications attain higher scalability.
Pub/Sub Messaging:
Redis offers a robust messaging system called publish/subscribe (pub/sub). This feature allows different components of an application or many apps to communicate asynchronously through channels.
Pub/sub messaging in Redis is helpful for developing real-time communication systems, event-driven structures, and message queues, improving distributed applications' responsiveness and scalability.
Ease of Use and Integration:
Redis is supposed to be simple and easy to use. Its simple API, thorough documentation, and support for multiple programming languages make it suitable for developers of all skill levels.
Redis interfaces smoothly with major frameworks, tools, and platforms, making it a useful tool for a variety of applications. Its ease of integration shortens development cycles and reduces time-to-market for apps that use Redis.
Scalability and High Availability:
Redis provides scalability possibilities via clustering and replication. Redis Cluster enables horizontal scaling over numerous nodes, spreading data and workloads efficiently. Additionally, Redis Sentinel automates failover and monitoring, ensuring high availability and fault tolerance. These capabilities make Redis a dependable option for developing scalable and resilient systems.
Limitations of Redis
While Redis provides various benefits, it is important to understand its restrictions or drawbacks:
Volatility of Data:
Most Redis operations are in-memory, meaning data remains in volatile memory. Data remaining only in memory is lost whenever the system fails, or power is lost. Although Redis has persistence solutions like snapshots and append-only files (AOF), this can have a performance overhead and might not give real-time data durability.
Memory Intensive:
Redis is an in-memory data store and hence can be, in case of large datasets or quite an enormous number of concurrent requests, memory-hungry. This may lead to an app environment with low RAM or memory resources, high memory utilization, and difficulties in scaling.
Single-Threaded Performance:
In other words, Redis is a single-threaded application: it executes the commands one by one, which are run on one CPU core. Such a design makes the handling of concurrency relatively easier and retains the consistency of the data. Still, simultaneously, it reduces the potential performance where parallelism is required in operation or involves a significantly large amount of work in concurrency.
Complexity of Operations:
Configuring and administering Redis for maximum performance and reliability may require some knowledge. Fine-tuning parameters such as persistence techniques, replication, clustering, and security configurations may necessitate a learning curve and continual maintenance, particularly in complicated deployment scenarios.
Redis vs. Memcached
Although Redis and Memcached are quite common in-memory caches, they still have some significant differences that make one suitable for specific needs. Redis is most often referred to as a data structure server because it is more functional and competent than Memcached.
The other apparent differences fall under data structure support. Redis supports diverse data structures, as mentioned above.
This flexibility enables Redis to support more advanced data operations, making it suitable for a wider array of use cases than just a key-value cache. Conversely, Memcached primarily works with key-value pairs and does not handle sophisticated data structures.
Next within this dissimilarity is another feature: persistence. Redis allows data persistence selections through the available snapshots and append-only files (AOF), thus enabling data recovery and durability in case of failure.
Memcached is a pure caching system with no built-in way of persistence. This makes it inappropriate for applications that require data durability. Both Redis and Memcached work fine in a performance-oriented environment, helping to provide low-latency access to the cached data.
However, because of its advanced data structures and command set, Redis frequently outperforms Memcached in instances requiring complicated data manipulation. Memcached's simplified architecture may provide a minor advantage in raw cache performance for basic key-value operations.
Scalability is an additional factor. Redis offers clustering and partitioning, which enable it to grow horizontally across several nodes. This makes Redis more suited for large-scale deployments that require high availability and distributed caching. While Memcached performs well, it may experience scalability issues compared to Redis in highly distributed or clustered environments.
Redis And VPSServer
VPS (Virtual Private Server) hosting is an excellent choice for Redis because to its flexibility, dedicated resources, and configurable configurations. VPS hosting allows users to designate particular resources to their Redis instance, such as CPU, RAM, and storage, assuring continuous performance and scalability.
VPSServer also provide isolation from other users, which improves Redis application security and stability. Furthermore, VPS hosting enables for easy integration with Redis-related tools and services, making it the best solution for hosting Redis databases and applications that require high-performance data storage and retrieval.
Frequently Asked Questions
Is Redis SQL or NoSQL?
Redis is, in fact, a NoSQL—not Only SQL—database. It is intended to work with unstructured or semi-structured information that comes as a key-value pair. Thus, it remains open to being an alternative to applications needing fast data access and caching without limitations, which are characteristic of SQL databases.
Is Redis a cache or database?
Redis acts as a cache and a database. It can save material that is often revisited in memory for fast access. As a database, it persists data to disk and uses more complicated data structures than caching. This versatility makes it worthwhile in several applications.
How is a new node added to the Redis Cluster?
Adding a node to a Redis Cluster involves typically the following steps:
-
Install Redis on the new node and ensure that it is properly configured.
-
To join the new node to the current cluster, run the redis-cli --cluster meet command, supplying an existing node's IP address and port.
-
The cluster will automatically discover and integrate the new node, spreading data across the cluster to ensure load balancing and fault tolerance.
How does Redis manage broken connections between clients and servers?
When a connection between a client and a Redis server fails, Redis normally terminates the socket and releases the related resources. Client-side libraries frequently handle reconnection attempts transparently, allowing clients to rejoin and restart operations without manual intervention in most circumstances.
What is a Redis command?
A Redis command is a set of instructions or operations delivered to the Redis server to carry out specified tasks, such as data storage, retrieval, data structure modification, transaction management, or administrative chores. These instructions interface with Redis and manipulate the data stored there.

Bilal Mohammed is a SOC analyst and cybersecurity expert who is passionate about making the internet safer. He has expertise in penetration testing, networking, network security, web development, and security operations center (SOC) services. In his spare time, he looks for security and design vulnerabilities to protect against attacks from hackers.




